How is is possible that we’ve made incredible gains in the performance of models, but virtually no gains in the infrastructure that supports them?.
.. or what I like to call: the worst enemy of chatbots is page refresh.
There are some large GIFs in this article, let them load :)
Claude vs. Page refresh
If a picture speaks a thousand words, here is a GIF of the Claude UI taken on 11th Feb 2026.
In this GIF you can see the prompt submitted, and Claude starts to stream tokens to the interface. Then I hit refresh and the stream stops. The page goes all skeleton-ui and eventually I’m back to the prompt input box, but the response is lost. Hit page refresh again, and the full response is available.
What’s going on?
Claude is using EventSource, which is a web API interface for SSE (Server-Sent Events).
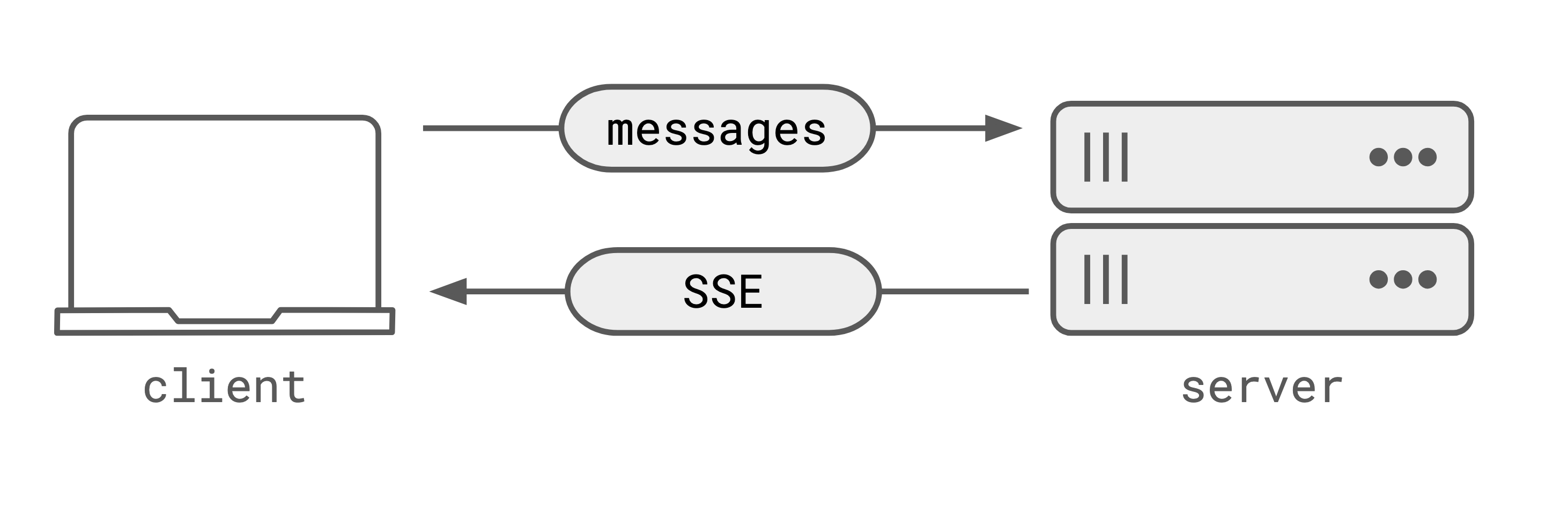
- Claude UI is taking all the current context in the chat window (all the messages) and POSTing them to the Anthropic servers.
- The full set of messages are passed to the model, in this case Sonnet 4.5
- The client leaves the HTTP connection open, and the server starts streaming SSE events as the model generates tokens.
Below is a simplified version of the SSE stream that is being sent to the client.
| |
So when the page is refreshed, the client disconnects from the SSE response stream, and doesn’t have access to the tokens the server is generating (or has already generated). Because the previous SSE responses are not accessible in any way, the UI shows no conversation history until the response generation from the model is complete. At which point, refreshing the page is showing the full response (which has been saved to some database as the ‘chat history’) and is being served from there.
Ultimately, the problem here is that the request-response paradigm between the UI and the model is stateless. So once the connection is lost, the client has no way of retrieving it.
What are folks doing to get around it?
For a lot of folks, the answer is: nothing. I mean, look at the Claude UI, it does a pretty terrible job.
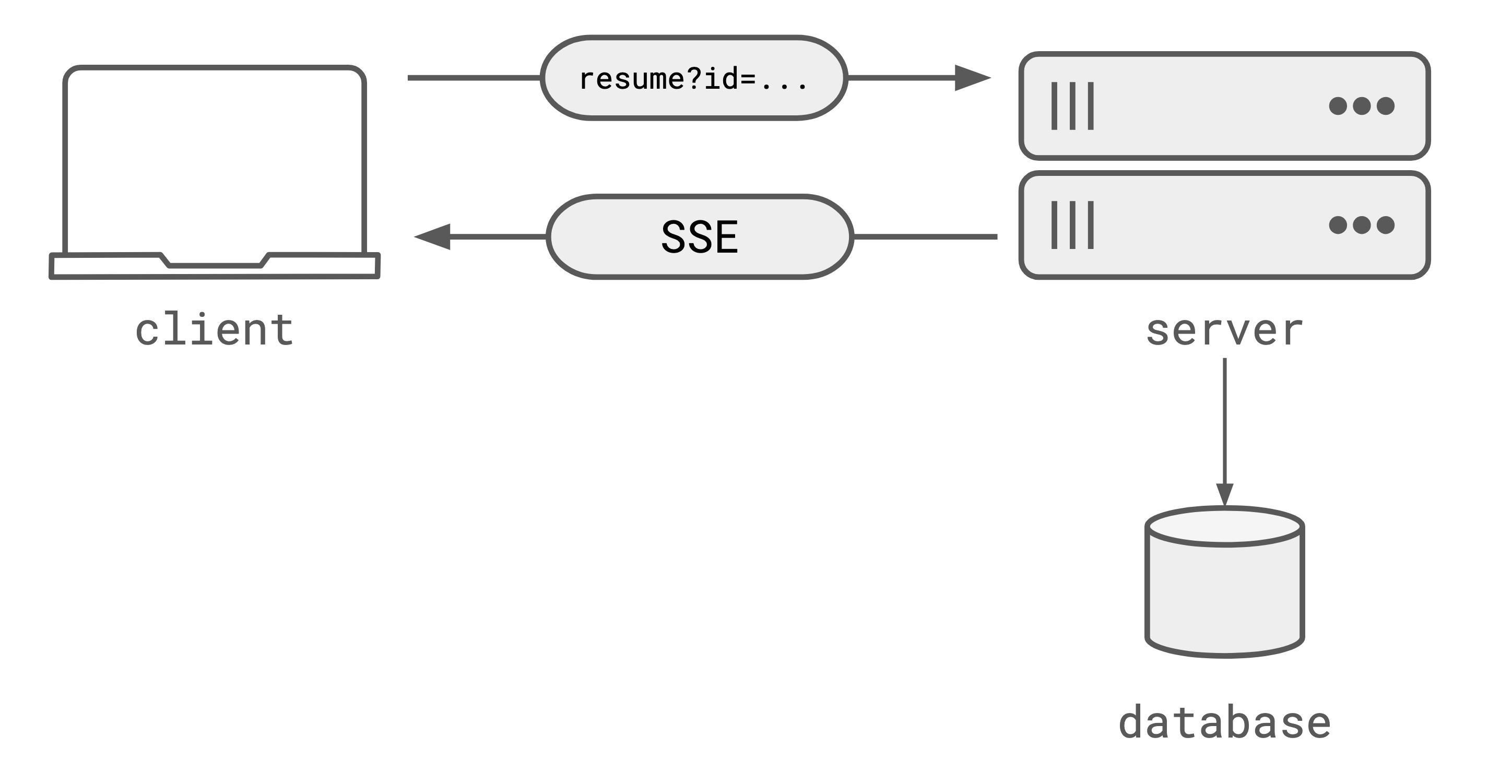
Well most folks are opting to store the individual SSE events (or the content of the events) in some
database. Typically something like Redis. And then implementing a resume endpoint that allows the
client to resume the SSE events from the last point they received. Essentially, this design is
writing every token to a database, just in case the connection drops.
Minimal chat vs. Page refresh
Now have a look at this GIF of a Minimal Chat UI I built. Each screen flash is a full page refresh.

In this example, you can see that I refreshed the page three times. You can see the page refreshes because the minimal example I built flashes the whole screen. But what you can also see is that the conversation history returns pretty much immediately, and the token stream is resumed seamlessly from the point it dropped on page refresh.
This example isn’t built on SSE, it’s built on WebSockets and Pub/Sub channels and backed by Ably. There’s also no database in this example. In fact, I implemented no persistent state at all to make the minimal example work. Chat history, token stream resumes, reconnection, it all just works.
This isn’t really about SSE though
Here’s the thing, this isn’t really about SSE. I mean, yes, SSE is a convenient extension of the regular HTTP request-response patterns that we’ve all been building apps with for ages. We are all familiar with it, it works with HTTP load balancers and stateless backends. But we’ve hit the ceiling for SSE. That terrible Claude UI refresh gif is state of the art for SSE. And it sucks.
It’s also not about WebSockets being better than SSE; which they are as you get a bi-directional stream of messages. It’s easier for the client to steer the conversation in real-time, and it’s easier to implement a single server process that’s handing a single conversation (as the connection is stateful once it’s established). But even with a bidi-stream, you’re not getting that good page refresh experience without storing session/connection identifiers, and having the client re-request the stream with those ids, and having the server look up the current conversation and calculate the individual missing tokens to send to the client. You still have to manage both connection/session information, and progress information for how far that client has progressed in consuming that token stream.
The art of the possible
This is more about expecting more from our tooling and infrastructure. This is more about knowing what the current art of the possible is. And right now, the art of the possible is way ahead of SSE.
The art of the possible right now is:
- Reconnection / disconnection handling
- Multiple devices / Multiple browsers for the same user
- Multiple users (collaborative / shared conversations) like OpenAI group chats
- Conversation history and Persistence
- Awareness (knowing when there’s actually an agent listening or processing your request)
- Token compaction and efficient hydration (not having to stream every delta each time you load the UI)
The point is, you just can’t do all these things with SSE. And if you try, you end up with some Frankenstein solution to hodgebodge a solution that’s a patch to the actual problem; that single connection SSE like this just isn’t a suitable transport.
What does better look like?
That’s why I’m loving working on an actual transport for AI. It turns out, that pub/sub messaging platforms are uniquely suited to solve all the problems mentioned above. They are designed for real-time messaging, they are designed for reconnection and disconnection handling, they are designed for multiple devices and multiple users, they are designed for presence and awareness, and they are designed for efficient message delivery.
In the last few months we’ve added “message.append” as an action you can take in Pub/Sub. This forms the core of the token streaming product. You create a message, and then you append each token delta to that message as it’s received.
The really cool thing is that for clients that are continuously connected during the token streaming, they see each token as it’s appended to the message. But for clients that disconnect and reconnect, they receive a “message.update” that contains all the tokens up to the point in the stream that they connected. This is way more efficient than having to stream every single token delta each time a client connects, and it also means that clients that are connected during the stream get the real-time experience. Clients that reconnect get a seamless experience without having to worry about missing tokens or messages. And the agent can advertise it’s “presence” on the channel so that clients know that someone is there actually working on their request. When the agent disconnects the “presence” is updated automatically, even if the agent crashes.
One message is one LLM response, and you just append the tokens to that message, and everything else just works. You can load conversation history from the channel, you can bi-directionally stream messages letting the client steer the conversation in real-time, and you can do all this without having to implement any of the complex logic around storing tokens, resuming streams, handling disconnections, or any of that stuff.
I think this is probably the coolest thing that I’ve worked on recently, and it’s so frustrating to see folks fighting with designs built around SSE just because the AI models have progressed, but the tooling and SDKs and infrastructure hasn’t.