Article originally posted on medium.com
–
When building a SaaS application, there are some similarities between apps, regardless of the service that they provide. This article lays out some of the most common cases, and the errors that it’s easy to make. We all have pre-conceived notions of how some flows should work, e.g. “login”. Perhaps those notions do not well translate into a flexible data model that allows for changing requirements. Below are some “rules of thumb” to help avoid some of the most common pitfalls. This is not meant to be an extensive of definitive guide, only food for thought. The examples below use a mixture of relational and document store modelling. The examples are only to support the point being argued and not to serve as a reference implementation.
separate accounts and identities
All SaaS applications have some ability to “log-in”. This is generally an email and password. Generally email and password are properties of a user.
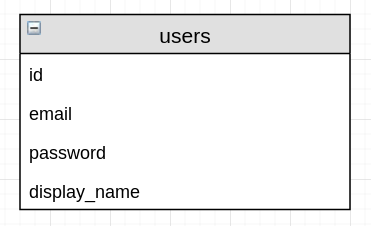
This is inflexible as it closely couples user with the means of idenifying one-self. A user is thought of as an email and password combination in this model. Imagine a change in requirements to include google-single-signon, or email-magic-link, or even API key access. How would this work given a user is an email and password pair? Instead of user, we should have accounts and identities. Accounts are the record of the human-user within the application. Identities allow the user to identify with the account. Different identification, access, and login methods can now be used agains the same account. Identities could include: google sso, email and password pair, API key etc.
| |
separate pricing plans, billing, and feature sets
As a SaaS, you probably want make money. One of the easiest ways of communicating different prices and levels of value to a potential customer is through staged or tiered pricing plans. These are common in many large SaaS apps.

Plans have two main parts: billing, and feature sets. Billing is “how much” and “how often” you pay. It’s £7.99/month, or £50/year, etc. Billing consists of some monetary amount and some time-period in which to charge that amount.
The second part of plans is “feature sets”. These control “how much” of the application you have access to. In almost all cases; the more you pay, the more you have access to. This is basic SaaS economics. It also allows users to try some of the product to understand its value before committing to a big spend.
From a data-modelling perspective, the core models “billing” and “feature sets”. These concepts should be modelled seperately and allow for different billing and feature sets to be combined. This allows flexibility in the sales pipeline and allows for customisation of the plans.
pricing_plans should be a template for what a user can buy. They should contain billing and feature_set
information. Modelling them as a “template that can be applied to a user” allows for different feature sets to be customised onto a specific user, and for discounts and modifications to billing.
resources owned by teams, not accounts
B2B SaaS apps will, at some point, need collaboration features. Teams are made up of multiple individuals and they expect to be able to work together. Good examples of collaboration features are Google docs, Dropbox paper, Intercom etc.
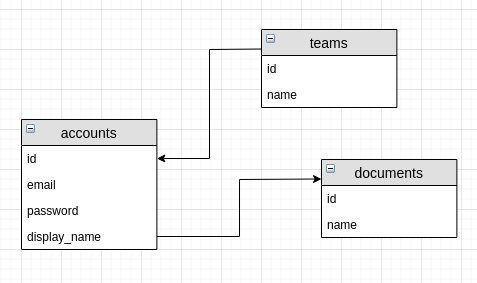
It’s important to appreciate the extent to which collaboration features impact the data model. Within each SaaS application, there will be some core model or resource. Using the Dropbox paper example, these could be “documents”. Imagine if the documents where all “owned” by accounts (users). Or in words; the hierarchical relationship modelled documents as a child of accounts. Assume again that accounts are grouped into teams.
To be able to collaborate on a document, the application would need to traverse the team to find all the accounts, then traverse all the accounts to find all the documents that a user could collaborate on. Each of those documents would need to have permissions about which other users could see and edit them. This becomes a confused hierarchy.
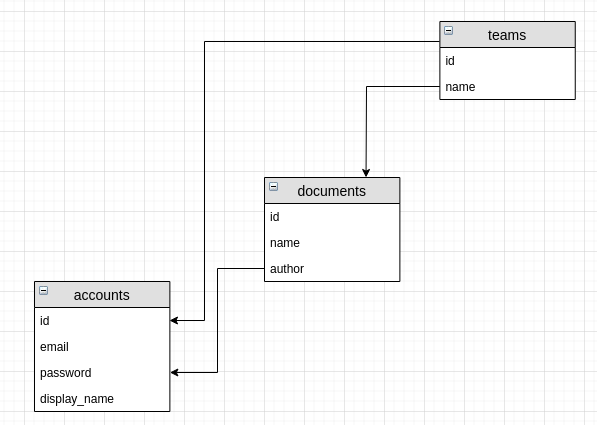
Instead, making documents owned by teams and having an understanding of who was their original author allows for collaboration to be built around groups of accounts (users) and not through deep traversal of a model hierarchy.
store the history, compute the sum
In some parts of the application that you build, there will be an aggregated value. This could be:
- Amount of CI build time consumed (minutes)
- Number of documents stored
- Number of users in a team
- Number of credits spent this month
In some of these cases it will be tempting to store an aggregated value. e.g. When a CI build runs, increment a counter of the total amount of time taken, when a new user joins, increment a database column for the number of users in an organisation, when a credit is spent decrement the balance remaining, etc.
I would characterise this approach as storing the “second-order” values. First-order values (in a server montioring context) are the original values, the number of servers, the cpu usage etc. Second-order values are what you can compute over the first-order values; average cpu usage in the last hour. By retaining the original first-order values, you have much more flexibility on what you want to measure (and understanding of how the end result occurred).
With this in mind, it’s more convenient and safer to store the first-order SaaS application values (# document, # users, etc) and then perform aggregations over those to get the second-order values. It’s likely that your database technology will be able to handle much larger aggregations than you will need to perform. This is especially true if you SaaS deals with user-generated content and not computer-generated (e.g. documents and users, and not clicks and page views). Only if you run into performance issues should you consider pre-calculating the second-order values.
separate the concerns
Most of the modelling patterns laid out above consist of thinking about each of the models as more separate than they originally appear. This separation allows for the requirements to change and the models to be able to handle that change.
A final note; the model that a human-user of an application experiences is not always the best model for the structure of the data. Consider how to decouple and separate the individual components of what the human-user perceives.