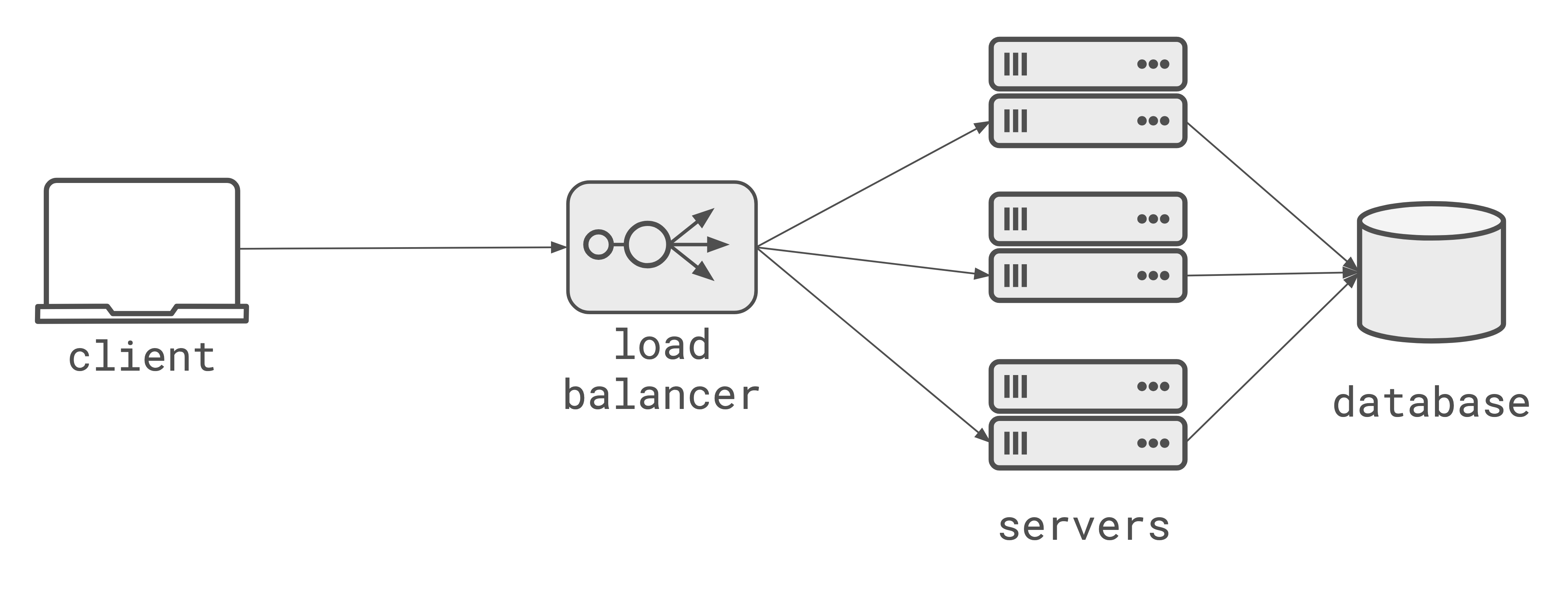
The ‘cloud-native’ architecture of the last decade is built on a 20-year-old assumption: that state lives in the database, and compute is stateless. If you want to scale, you scale the database vertically (get a larger machine) [1][1] or design the database schema around partition the data and you scale your application servers horizontally (add more boxes). Any request can hit any server, the loadbalancer doesn’t care, and the database is the single source of truth.
LLMs and agents are quietly violating this assumption, and making this architecture increasingly hard to work with. Not all at once, but in three subtle ways:
- Long running work: an agent doing a 10 minute task isn’t a ‘request’, it’s a long-running async process.
- Stateful compute: an agent might run multiple turns of a conversation, might process multiple tool calls, and relies on accumulated context. That state is not really ‘database state’, it’s the agents memory.
- Bi-directional interaction: the user wants to watch the agent think, to interrupt it and redirect it. That’s a conversation with a process, it’s not a query to a stateless API and database.
Durable execution solves part of the problem
Durable execution (Temporal, Inngest, Restate) is the industry’s current answer to the execution part. It makes the process durable and resilient. But we’re still pretending it’s stateless underneath. This works for the execution but doesn’t solve the interaction problem.
So the moment a client wants to talk to a process running in a durable execution framework, you’re back at the same routing problem. And so everyone reverts to polling. Poll a query endpoint to get the latest updates that the durable execution process wrote to a database.
It’s a universal workaround, but it still sucks for all the same reasons that polling sucks; latency choices around how often to poll, database load, wasted requests, terrible UX for streaming.
Ultimately, polling treats your database as a message bus. Which is what folks did before actual message buses existed. Polling is what you do when you can’t figure out how to address the thing you want to talk to. It’s a work around for a routing problem.
There’s a missing routing primitive
The foundational assumption about how we build web services is breaking. We’ve been designing using this architecture for so long that we forgot it’s even a choice. But we’re missing a fundamental routing primitive that HTTP, loadbalancers, and the stateless server design can’t solve.
We want to be able to say; “deliver this message to whoever is producing output for workflow X”. Without needing to know which box, which server replica, which process that is.
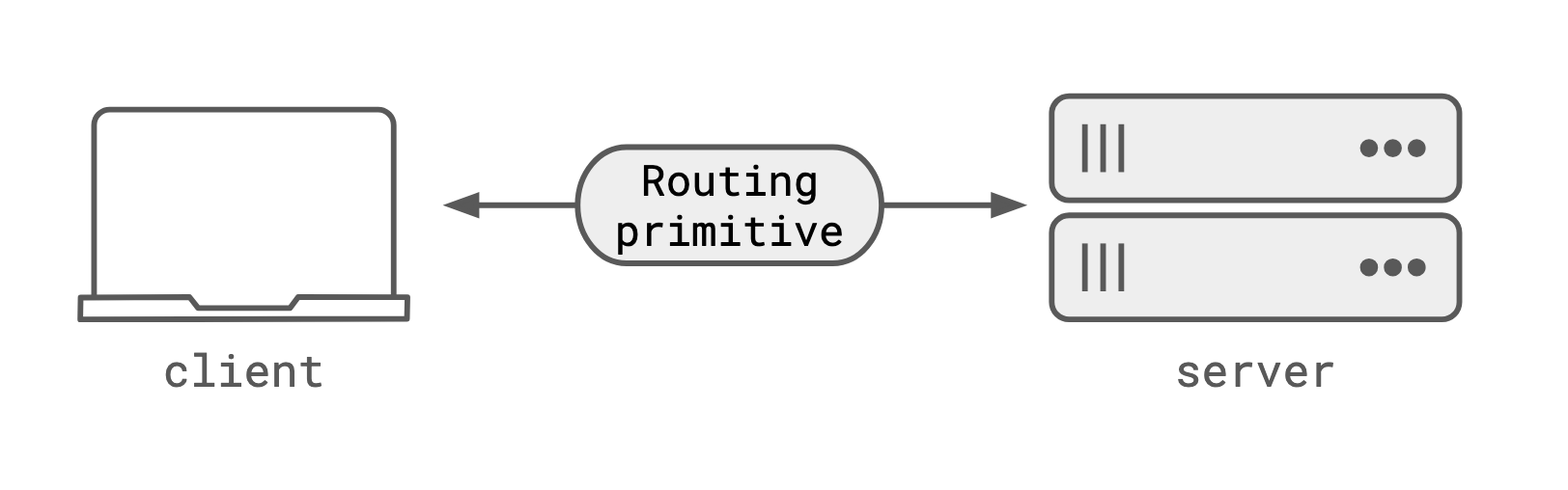
Maybe it’s WebSockets?
Looking at the image above, it looks like WebSockets could drop in fairly easily in the box labelled “Routing primitive”. They are a transport that supports a long-running bi-directional connection, and connect a server process to a client.
But WebSockets have a problem: they are a connection, not an address. They solve the routing problem once, by creating a direct connection between client and server. But if that connection drops, the ‘address’ is lost. You can’t reconnect to the same process, because you don’t have an address to route to.
It’s pub/sub channels
Pub/sub channels invert the ownership. Neither the server process, nor the client is addressable. The transport is addressable. Both client and server connect to the pub/sub channel by name, and get bi-directional, stateful communication. The channel is the address, and unlike WebSockets, it’s not a connection. It’s a durable channel that you can disconnect and reconnect to without losing data or the ability to route to the same process.
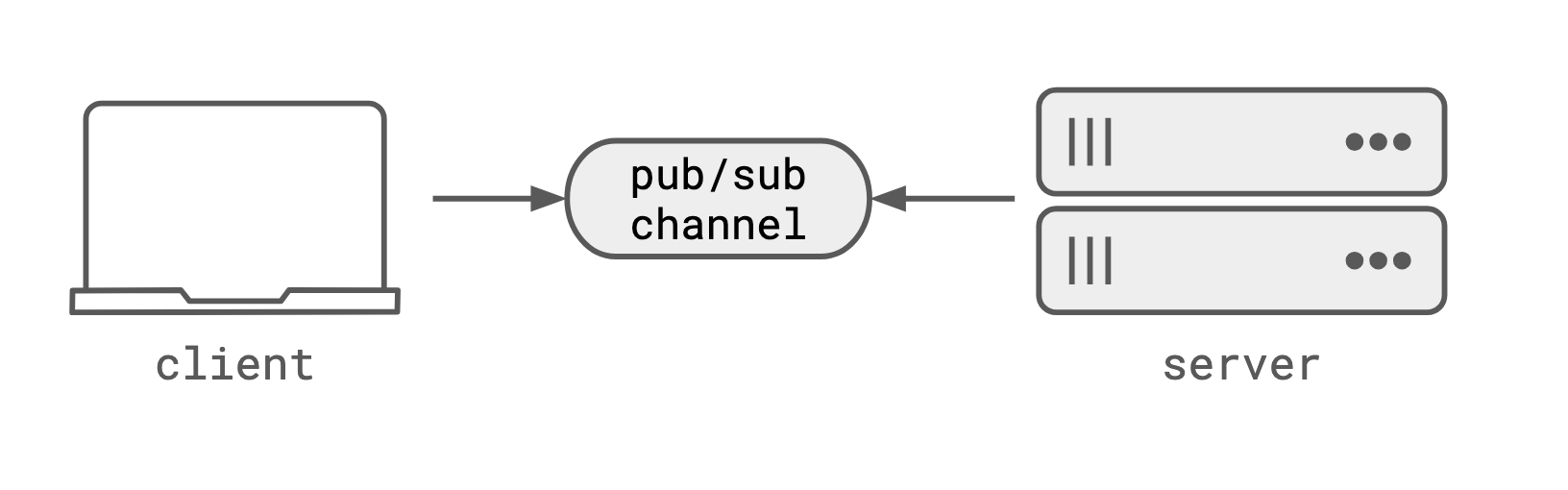
Durable transport for durable execution
Back on the Temporal example, the durable workflow activity (or step) would connect to a pub/sub channel named after the workflow ID. The client would connect to the same channel to get updates, and send interrupts or steering messages. The workflow would be durable, and the channel would be durable, so even if the workflow process or the client connection dropped, they could reconnect to the same channel and keep talking to each other.
You don’t have to thread data through a database, you don’t have to poll, and you don’t have to worry about not being able to address the durable process that’s actually doing the work.
This isn’t really about LLMs though
LLMs just make this problem more visible. Before, if the connection dropped, the request would be cheap enough to retry and you’d likely be getting a deterministic response. Retries are simpler when you can expect to get the same response to the same request.
But that’s not true for LLMs. LLM responses are not deterministic, and are not cheap. If you’re paying for tokens, you don’t want to waste them because the client went into a train tunnel and the connection dropped. You also don’t want to have to thread every token through your database, just to make it resilient to client connection issues.
By being non-deterministic and expensive, LLMs make the limitations of our current architecture more visible, and make the trade-offs of HTTP + stateless server + loadbalancer + database more painful.
The stateless web isn’t wrong, it’s just not a good design for agentic applications, that want long-running, stateful, interactive processes. We need a new architecture that includes a routing primitive that can address processes, not just databases.
Durable execution + pub/sub + stateless HTTP; each doing it’s own job.