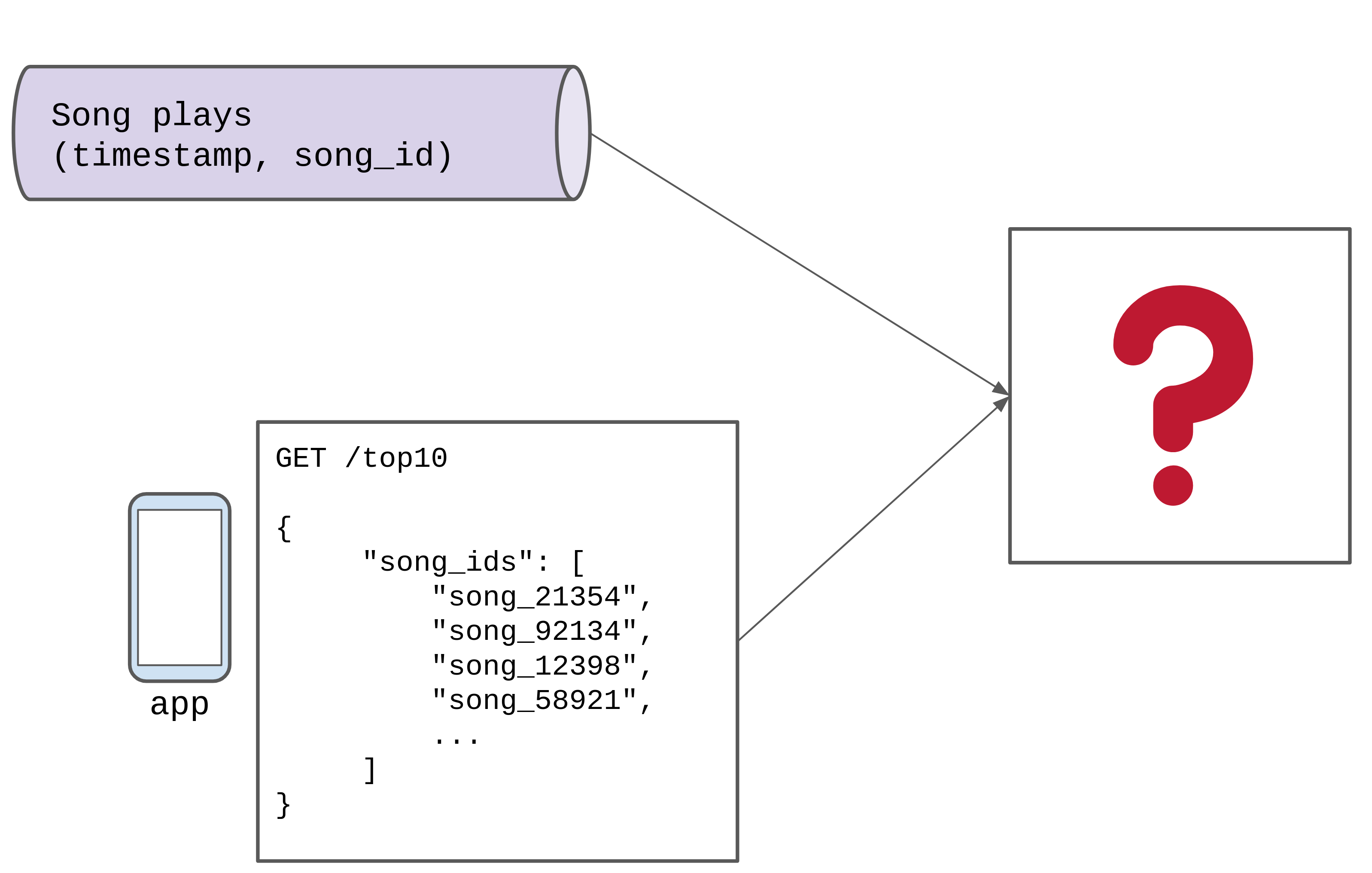
Imagine you’re presented with this problem:
Design a system that can show the top 10 most popular songs over the last 10 seconds on the homepage of a music streaming service.
You have access to a queue of events representing song ‘plays’ with a
(timestamp, song_id)tuple.The data should update, and be as fresh as possible.
We are given this to work with, we need to design a system that satisfies the requirements, replacing the “❓”:
This is basically a window-based streaming aggregation problem. The window is 10 seconds, we want the top 10 most played songs in that window.
Boring solution: ksqldb
The boring answer is to use some tool like ksqlDB does the window aggregation for us, and emits the results to a new queue. We can store the values of that queue, and do a simple lookup:
| |
Each time we receive an event from the aggregated queue, we can just replace the row for that song_id as we know that the aggregated events contain more recent data than we have
in the datastore.
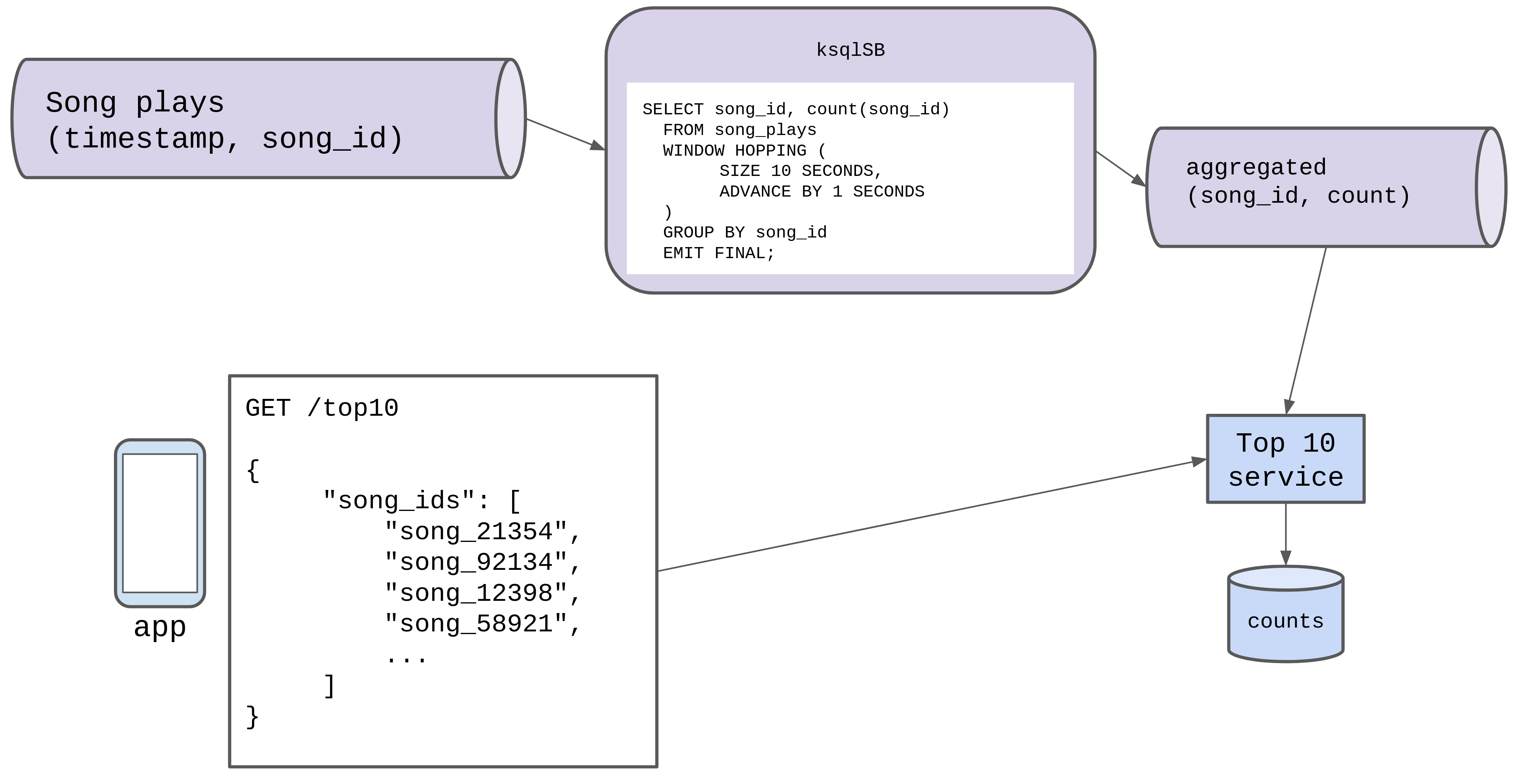
But how does it work?
First, we’re presented with an unbounded data stream. The queue of song plays has no ’end’, users will continue to listen to songs (hopefully) forever. Because there’s no end, we design the ’top 10’ most played based on song plays in the last 10 seconds.
To get the data for the last 10 seconds, we “window” the unbounded data stream into 10 second chunks.
Windowing
When we talk about windowing, there are a few different terms we need to cover.
- Aligned vs. Unaligned windows
- Sliding, Fixed, and Session windows
- Skew
Aligned vs. Unaligned
The events in the queue song_plays have a key (song_id) and a timestamp.
If we want to make a 10 second window over these events (for example, count the number of plays for each song_id within 10 seconds),
we have to decide if our windows will be aligned or unaligned across the song ids.
- Aligned: in an aligned window, the window covers a time period regardless of the keys found in that period.
In the image below this means the aligned window starts at time
t1for both keyAand keyB. The window size here is 5, so we find 3 events with keyAand 2 events with keyB. - Unaligned: in an unaligned window, the window covers are time period specific to each key.
In the image below we can see that there are now two windows, one for key
Aand one for keyB. Both windows are size 5. Now we find 3 events with keyAand 3 events with keyB.
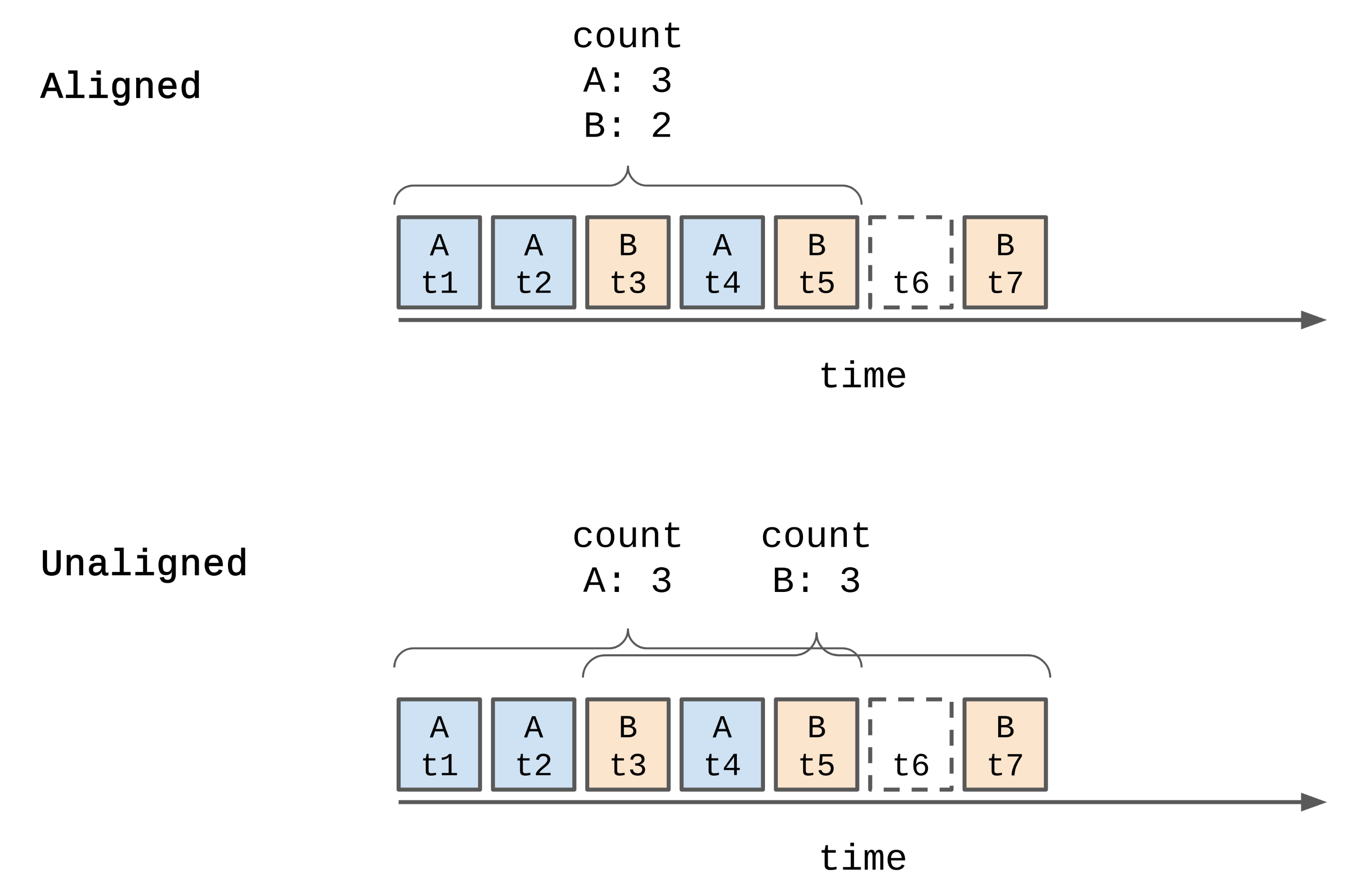
Given we want to get the top 10 songs regardless of their IDs, from now on we will consider only aligned windows.
Sliding and Fixed windows
A sliding window (sometimes called a hopping window) has two parameters:
- Size: the size of the window
- Period: how long before a new window is created.

In the image above we can see the effect of a sliding window, we actually have 5 different windows in the image. Each window is size 5 (i.e. 5 seconds long), and a new window is created every 10 seconds.
In our original ksqldb query we have something really similar to this:
| |
Ksqldb calls this a ‘hopping window’, but we have a window of size 10, and we create a new window every 1 second.
We can expect this query to emit the aggregated event for each song_id every 1 second, and that event will contain the last 10 seconds of data.
There’s a special case of sliding windows call “fixed window”, where the size and period are the same. Fixed windows are sometimes called “tumbling windows”.

In this image we can see that there’s no overlap in the windows. This is because the window size and period are the same. That is; a new window is only created every 5 seconds, and the window covers 5 seconds of data.
Session windows
The final kind of windowing is called “session” windows. Session windows are configured by a ’timeout’. New windows are created when the timeout has elapsed and a new event for a key is received.
This has the effect of grouping series of events that occur faster than the timeout into a single window. Windows are not a fixed size, but are based on ‘activity’.
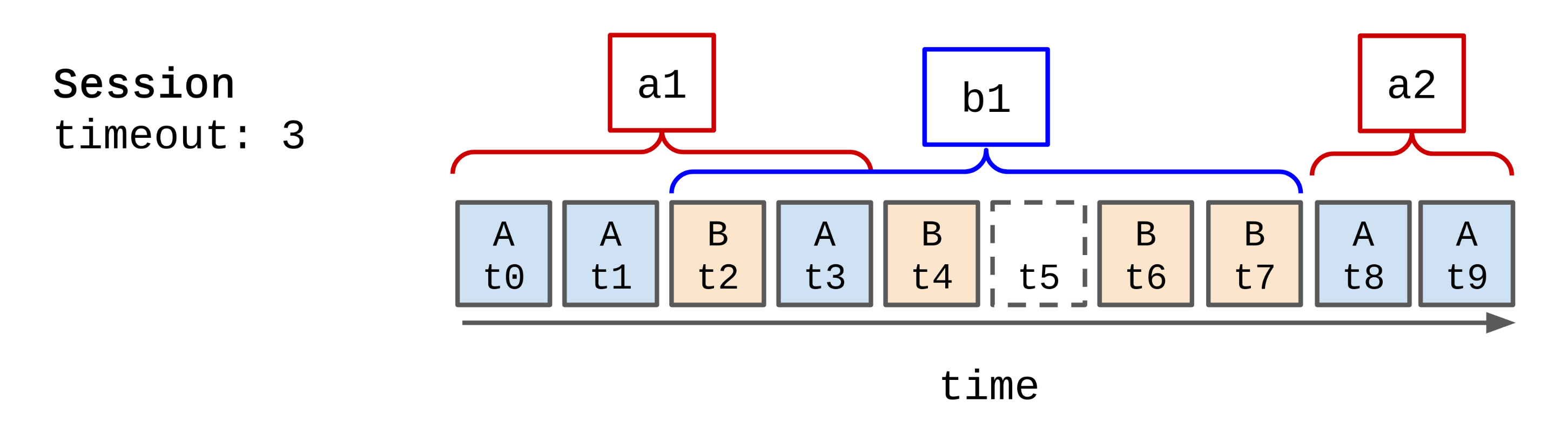
In the image above we can see that there are 3 windows, 2 for key A and 1 for key B. The timeout is set to 3.
This means a new window could be created for key A after t6 (i.e. t7 onwards, last event for key A was t3 plus the 3 second timeout).
But no new windows are created until an event for key A is found. The new window for A starts at t8.
This would be useful if we wanted to track user activity. Maybe we wanted to record the number of songs each user listened to during each use of the streaming application. We could define “each use” as user activity separated by 10 minutes, set our session window timeout to 10minutes, and record the activity.
Session windows are unaligned (because they are specific to the event key).
Skew
Skew is what happens when the events we process are not ‘fully ordered’ in some way.
If we take the top 10 example, imagine that the song play events we receive contain a timestamp that’s given by the app the user is listening on. We can expect that the song play events in the queue won’t be exactly ordered in time. Some earlier events will have later timestamps, and some later events will have earlier timestamps.
We call this skew.
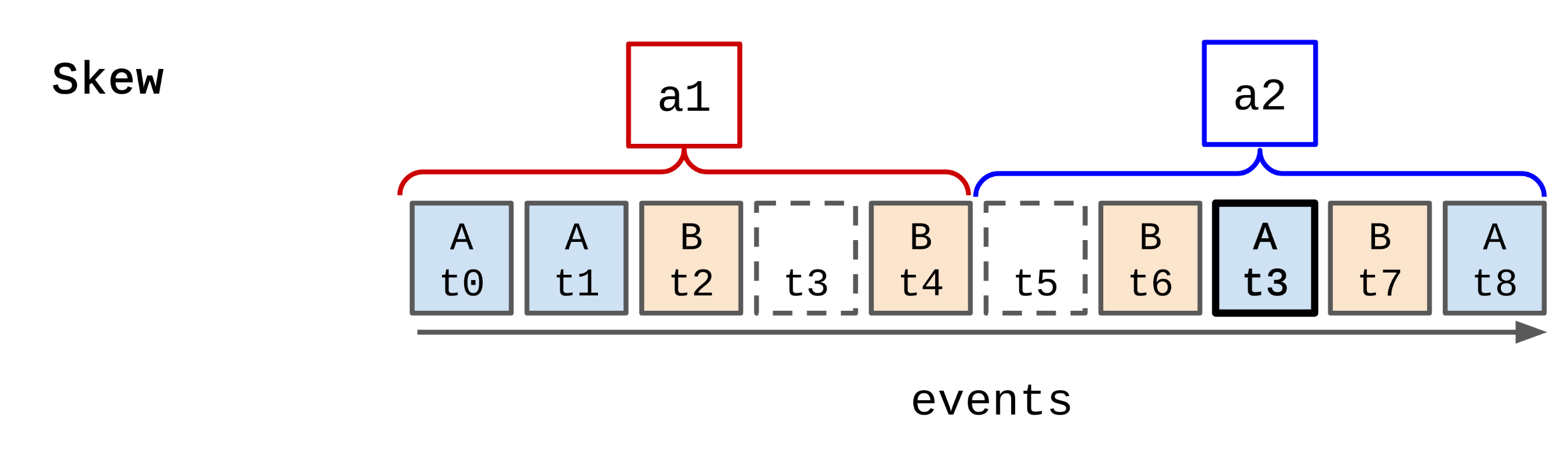
In the example above we can see that the event with key A and time t3 appears in the queue out of order.
The event should have counted towards window a1, but is falling withing window a2.
We’ve got a choice here, which can only really be decided based on the problem domain. Lets also assume that it would be wrong to count the event in window a2.
- Recalculate window
a1and publish a correction for that window, ignore the event from windowa2 - Ignore the event in window
a2.
For our top 10 feature, given the data doesn’t need to be perfect or exact, and the windows are changing often, it’s reasonable to ignore the event entirely.
Once we pass window a1 there no real value in going back and changing its values, given the top 10 service will be using the data from window a2.
But; if we were building a billing application on streaming data aggregation, it’d be important to make sure that window a1 was correct.
In this case we would go back to window a1 and recalculate it given the new event.
Recalculating windows can become messy quite quickly. You need access to some or all of the data from previous windows in order to recalculate them, which means holding on to that data. There’s a tradeoff to be made between how long you want to go back in time to recalculate, and how much data from previous windows you have to hold on to.
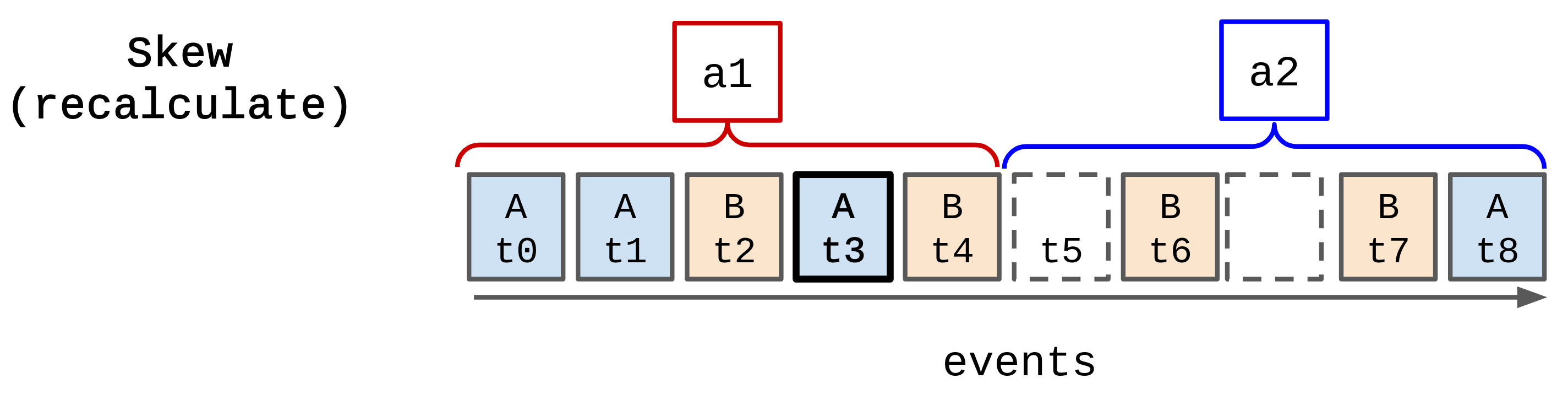
To recalculate we need to artificially insert the new event into the correct window. For a simple case like adding the values we can do that on top of the already aggregated value. But for more complicated aggregations we might need all of the underlying events to recalculate the window from scratch.
Solving the top 10 problem (manually)
Almost all streaming data aggregation frameworks and tools use time-interval buckets. They take the timestamps of the streaming events received and group them together, e.g. into 1 second buckets.
These buckets are then aggregated into windows.
So far in our examples, we’ve only dealt with 1 song being played at any given time. Clearly multiple users of our streaming service will be playing the same song at the same time.
So solving this manually we would create time buckets (e.g. of 1 second) for each song_id, and track the counts against those buckets.
| song_id | timestamp | bucket | accumulation |
|---|---|---|---|
| A | 12:00.1 | 12:00 | 1 |
| A | 12:00.3 | 12:00 | 2 |
| B | 12:00.4 | 12:00 | 1 |
| A | 12:00.5 | 12:00 | 3 |
| B | 12:00.9 | 12:00 | 2 |
| A | 12:01.2 | 12:01 | 1 |
| A | 12:01.6 | 12:01 | 2 |
| A | 12:02.0 | 12:02 | 1 |
These events then flatten into (song_id, bucket, count):
| song_id | bucket | count |
|---|---|---|
| A | 12:00 | 3 |
| B | 12:00 | 2 |
| A | 12:01 | 2 |
| A | 12:02 | 1 |
Then, every 1 second we would sum up the buckets for the songs over the last 10 seconds (size: 10, period: 1), and output the total count for each song_id. Using the example data above we’d get:
| song_id | window | count |
|---|---|---|
| A | 12:00,12:09 | 6 |
| B | 12:00,12:09 | 2 |
From now on, we don’t strictly care about the specific times in the window. We just know that every window event we get out will be the most recent counts for that song_id. We can store and query those counts in our top 10 API.
Expiring old data
For any given song, if that song was played in the last 10 seconds, we expect to receive an new event for that song every 1 second. This means we can pretty aggressively expire the data in our top 10 service’s data store. If we haven’t received an event for a song in 2 seconds (2x the expected rate) then we can delete that song entry from our top 10 store. This solve the problem of a song’s count not being updated because no one is listening to it. If no one is listening, then the song will be dropped from the store.
Optimising the store
Given we know that the events we receive in the top 10 service represent the count for each song_id over the last 10 seconds. We don’t need to store the count for every song_id. We only need to store the count for the top 10 songs.
Each time we receive an event of (song_id, count) we can:
- Check if that
song_idis already in the top 10, if it is, replace current the count value. - Else, if the count on the event we received is larger than any of the current top 10, insert that
song_idand count, and drop thesong_idwith the lowest count from the store.
Now there will only ever be 10 rows in our top 10 service’s store, and returning the top 10 data in the API call will be super fast. Given the aggregated queue holds the events, we could reasonably keep the top 10 songs in memory and re-build that state from the queue if the top 10 service crashes.
Making it scale
We aren’t too worried about the top 10 service, or it’s store (for the reasons above). So we mostly have to worry about the bucketing and aggregation.
Assuming our input queue is partitioned in some way (that is we can register multiple disparate consumers on the queue, where each consumer is guaranteed to receive all events for a specific key) then we can scale our bucketing and aggregation horizontally.
We can have multiple song_plays consumers processing plays for a sub-set of the keys and publishing the counts for those keys.
If the number of song plays for a specific key in a specific 10second time window is too large for any single consumer to process, then we would have to split the 10 second window into smaller chunks, and add another stage that would merge together sub-windows (say 5 fixed windows of 2 seconds into a sliding window of 10 seconds).
Reduce the throughput
We could change the period of our sliding window to a larger value, say 3 seconds. This would reduce the rate at which aggregated song plays events were published for each key to once every 3 seconds, rather than once per second. We would be sacrificing some of the reaction speed and freshness to reduce the volume of data the top 10 API had to consume.