When solving problems using a computer, we assign “time classes” or time complexities to the problems to describe how long that problem will take to solve.
They look something like this image;
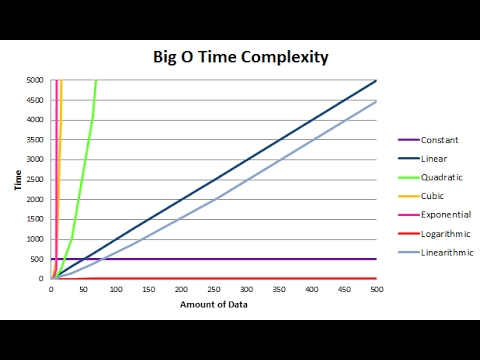
You can see on this graph the difference between the “amount of data” and “the time taken to find the solution” (e.g. process the data).
“good” time complexity
Most problems are linear, that is as the amount of data increase, the time take increases proportionally. Sending a different email to each team member is a linear task. As the number of team members increases, as does the time taken to send all the emails.
The best possible time complexity class is “constant”. Using the analogy; sending a single email to all team members at once. This takes a constant amount of time, as the number of team members increase, you just include more emails in the “To” section of the email, sending takes a constant amount of time (ignoring the time taken to input the email addresses).
“bad” and “ugly” time complexity
There are some awful classes of time complexity such as “quadratic”, “cubic”. In these, as the amount of data goes up, the time taken goes up more! These time complexities are called “polynomial”.
There’s a final class of time complexity “exponential”, which is the very worst case. The ugliest. Exponential time complexity problems are the hardest problems in computer science, and take a ridiculous amount of time to solve. Some examples are;
- Planning a sat-nav route between two cities.
- Working out the quickest way to deliver all my parcels.
- Creating a school timetable for classrooms, classes, and teachers.
- How to arrange shopping in a shopping bag to get the most items in.
the role of human intuition
For computers, finding the best solution to these problems would take more time than humans were prepared to wait, so most of the time an approximation is made (a guess, by the computer). The product teams building these computer systems have decided that a fast solution is better than a perfect one.
The weird thing is that; human “intuition” is kind of good at solving these exponential time problems. You could pretty easily look at your shopping and workout how best to put it in your bag, so as to maximise the number of items that fit. Or look at the few streets of houses to delivery post to and workout which route to take. But computers are very terrible at these things.
We have seen a pivot in recent years that started with IBMs chess playing computer deep blue. The pivot is away from relying on computer’s power to solve the problems, and towards “intuition”.
It takes too long to test every possible solution and find out which is best in chess, and in these problems. The invention of google’s go playing computer “alpha go”, much like deep blue, uses more “intuition” based decisions than it does computation based decisions. Which is why it’s such a massive achievement in computer science.
the greedy approach
Computers can only make short sighted decisions, they can look at two different options and decide which of them appears best. The series of short-term decisions can be added together to try and get a longer view, but that requires more data, and much more computation.
This approach of taking the “best decision now” is called the “greedy approach”, picking the immediately best option. But the best option in the short-term is, in many cases, not the best overall.
This is “local and global optimum”. For a computer, which has already made a local-optimum decision, it’s enormously difficult to efficiently “backtrack” to find the global optimum. Computers don’t really have that ‘sense’ of short term loss for long term gain, that humans do.
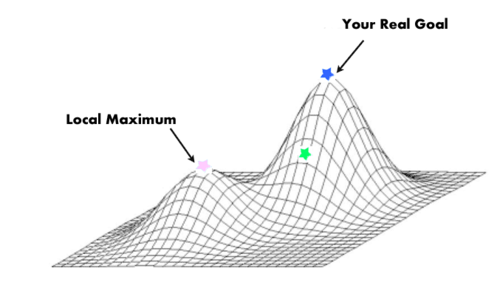
Using a greedy approach, it’s hard for the computer to justify leaving the ’top’ of the local maximum, as all steps it could take are “down”.
A computer can only process 1 datapoint at once.. probably the data that represents where the computer is right now, and / or the step it could take.
As a human, I can clearly see where the global maximum is, because I can understand the whole picture.
I mentioned that a series of short-term decisions can be added together to try and build a longer-term view, but this results in an exponential time complexity for the computer.
reducing the data set size with intuition
Back to the chess example, it’s really easy for a human to understand that a sacrifice of a particular chess piece will put them in a better position overall (or a better position in 4 moves time).
For a computer, this is very hard to do. Because it has to understand all the possible moves that could be made, and all the outcomes from all those moves. Which is a very large amount of data, which takes very large amount of time. (exponential time)
Hence the need to kind of mimic the human intuition.
Alpha go, the go playing AI developed by DeepMind and Google, used it’s experiences of playing previous games of go to influence it’s future intuition (decision making). This allows the software to reduce the complexity of the problem it needs to solve, by making ‘better’ approximations of the problem. Avoiding the exponential time complexity of the problem.
supervised learning
Many machine learning and artificial intelligence models use the previous experience of humans to power their decision making. This is called supervised learning.
Supervised learning can be thought of as encoding into the computer model that human “experience” or “intuition”. Rather than having to deal with the full data-set-complexity (or size).
The important thing with supervised learning is;
💩 in, 💩 out
The prediction that you make is only as good as the data that you have, the data that can be included in your decision making. If you have a bias in the collection of data, or observation of your environment, then you decision will be tainted towards that bias.
Perhaps; that data works to entrench your existing beliefs, rather than working to help make better decisions.